
CSAPP要点总结 第3章 程序的机器级表示 part3 汇编实现控制流
机器码提供两种最基本的条件行为,测试数据值,并根据测试结果调整数据流或控制流(jump)。
条件码
除了整数寄存器,CPU还维护者一组bit上的条件码(condition code)寄存器。这在王爽的《汇编语言》中称为一个状态位寄存器。csapp中也包括: CF:carry flag ZF:zero flag SF:sign flag OF:overflow flag 等等。详见:汇编语言 第11章 标志寄存器
需要说明的是leal指令虽然看上去像是计算,但实际上它是取地址,所以不改变条件码。
而,CMP指令虽然和SUB指令行为一样,但实际不改变操作数,但会改变条件码。
TEST指令则和AND指令行为意义,也不改变操作数,但会改变条件码,典型用法是测试数正数负数。
而INC、DEC会设置OF、ZF但不会设置CF(其中原因需要深入学习) 移位运算会将被移出位放入CF、设置OF为零。
访问条件码
当利用条件码来判断两数据大小时,常常是访问几个条件码的组合,比如说: (以下内容来自《汇编语言》)
对于无符号数,主要通过CF标志位和ZF标志位判断,如下:
以上结果是针对无符号数而言, 对于有符号数,判断等于、不等于根据zf判断,判断大小则考察sf和of
以上结果是根据sf和of的取值,判断大小关系。 如果是 <= 稍微麻烦一点,要么zf =0 或者 sf和of异号。
那么问题来了,如果是简单判断是否为零,只需要判断zf就可以了,
但如果是判断ax < bx,其中ax、bx为有符号数字呢?
如上式可知应该判断SF^OF,即SF、OF异号(见上)。
如果每次都这样处理,不仅麻烦,且不直观,因此,用一个语法来解决这个问题,就是set命令,例如setl D(set less to D)就是将SF^OF的结果给一个单字节的操作数D,如果ax < bx成立,则将会设置D = 1,如果不成立,则D = 0
同样的,其他的大小判断语法参见下表:
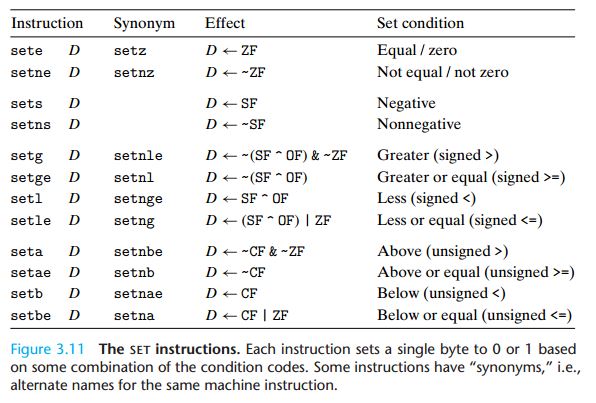
其中:
sete D指的是set equal
sets D指的是set sign,负数
setge D指的是set greater equal,(有符号数)大于等于
setle D指的是set less equal,(有符号数)小于等于
setbe D指的是set below equal,(无符号数)小于等于
setae D指的是set above equal,(无符号数)大于等于
其中操作数D可以是单字节寄存器,例如&al;或者单字节的存储器位置。
通常还要被8位的结果扩充到32位,高位补充0,因过于细节,不展开,相关指令是movzbl。
跳转指令及其编码
跳转指令分为无条件跳转jmp和有条件跳转。
其中无条件跳转可以是.标号(直接跳转,机器码将含有跳转位置)
或者是*寄存器(间接跳转),或者是*(寄存器)。
寄存器带括号实际上表示寄存器指向的内存位置,所以带括号的可以理解为指向指针的指针。
不展开。
有条件跳转只能是直接跳转,意思是,既然我什么时候跳转不确定,那总的把跳转的位置给确定了吧。不然别处乱子,而且还占用寄存器。
跳转指令汇总见下: (可见条件跳转指令跟set指令情况有些类似)
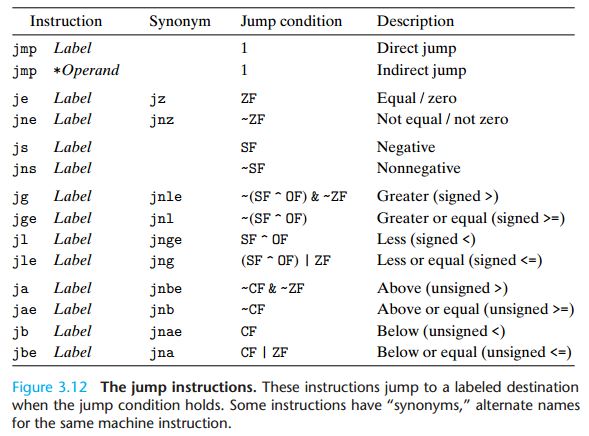
跳转指令的机器码编码有多种类型,其中最常见的是PC(程序计数器)相关的,所谓PC相关,就是《汇编语言》中的偏移地址或者说相对地址,是俩地址的差。这样PC指向某个位置时再叠加偏移量就是绝对地址了。其地址有1、2、4字节三种情况
另一种编码就是“绝对”地址了。其地址只有4个字节一种情况(这是32位的情况,所以寻址空间也被限制在4GB,而64位肯定不是这样的)
汇编器和链接器会根据实际情况选择用相对地址还是绝对地址。
用相对地址的优点就是指令编码更简洁(可以仅用2字节、甚至1字节),且目标代码可以不做修改地移到存储器不同位置。
条件分支
对于C语言的if-else语句,通常结果是如下的:
if (test-expr)
then-statement
else
else-statement
将其翻译为汇编,伪码将是如下形式:
t = test-expr
if( !t )
goto false ;goto 对应汇编中的跳转语句
then-statement
goto done
false:
else-statement
done:
注意了,来个复杂一点的情况:
如果test-expr是一个包含&&的情况,例如:
if ( aIsFalse && bIsTrue )
then-statement
else
else-statement
将其翻译为汇编,伪码将是如下形式:
if( !aIsFalse )
goto false
if( !bIsTrue )
goto false
then-statement
goto done
false:
else-statement
done:
有没有发现,如果第一句!aIsFalse为真,那么直接跳到else语句。也就不执行!bIsTrue语句。 这就是C的规则啊!由此可见C与汇编果然不是一般的关系。
如果test-expr是一个包含||的情况呢?
if ( aIsFalse || bIsTrue )
then-statement
else
else-statement
将其翻译为汇编,伪码将是如下形式:
if( aIsFalse )
goto true
if( bIsTrue )
goto true
else-statement
goto done
true:
then-statement
done:
这时把if语句内的表达式变成测真,并把then-statement和else-statement位置反一下即可。
可见在&&和||情况下都有各自对应的汇编表达形式。
循环
C提供了do-while、while、for三种循环方式,
而通常,大多数汇编器根据循环的do-while形式来产生汇编代码,
while、for则先转化为do-while形式。
do-while
对于C语言的do-while表达式:
do
body-statement
while (test-expr)
可以翻译为如下汇编形式:
loop:
body-statement
t = test-expr
if (t)
goto loop
while
C语言的 while循环表达式如下:
while (test-expr)
body-statement
为了得到其汇编代码结构,先将其转化为do-while形式,如下方法为常用形式,GCC也是这么干的,在开始的地方利用了一个条件分支。
if (!test-expr)
goto done
do
body-statement
while (test-expr)
done:
使用如上方法时,编译器有时候会优化掉开始的if语句,如果while可以确定发生的话。
for
C语言的 for循环表达式如下:
for (init-expr; test-expr; update-expr)
body-statement
这样的循环行为可以用如下while代码行为表示:
init-expr
while(test-expr) {
body-statement
update-expr
}
再按照上述方法,转换为do-while的形式,这里不累述了。
for循环的例子
do-while和while循环的例子也可以,但为了节约时间,仅研究一下for循环的例子
假设有如下的 forAsm.c 文件:
int fact_for(int n) {
int i;
int result =1;
for(i = 2; i <=n; i++) {
result *= i;
}
return result;
}
用gcc获得其汇编代码
$ gcc -S -O1 forAsm.c -o forAsmO1.s
获得的forAsmO1.s文件内容如下:
.file "forAsm.c"
.text
.globl _fact_for
.def _fact_for; .scl 2; .type 32; .endef
_fact_for:
LFB0:
.cfi_startproc
movl 4(%esp), %ecx #n => %ecx
cmpl $1, %ecx #if n <=1 return 1
jle L4
movl $1, %eax #set result to 1
movl $2, %edx #set i to 2
L3:
imull %edx, %eax #result *= i
addl $1, %edx #i++
cmpl %edx, %ecx #if n >= i
jge L3
rep ret
L4:
movl $1, %eax
ret
.cfi_endproc
LFE0:
.ident "GCC: (GNU) 4.9.2"
其中分号后面内容为我添加的注释部分,和书本中的内容几乎一致,O2/O3有部分辅助的伪码不同。
而不添加任何-O的版本将尽可能少用寄存器,例如%ecx,%edx 取而代之的是在栈中,另辟空间存放中间值。
条件传送指令-分支预测
条件指令的相关关键词实际上是现代CPU的流水线作业、分支预测
cmov指令格式与用法
条件传送指令是compare mov指令,汇编写为cmov后缀,同时后缀说明大小判断,例如cmovl中l指的是less,跟jl指令类似。jl是如果小于成立,则跳转
而cmovl指的是,如果小于成立,则赋值。
例如:
cmpl %ebx %eax #compare long, %eax : %ebx
cmovl %ecx %edx #mov if less, if %eax < %ebx then mov %ecx %edx
cmovl a b指的是如果
例子
需要注意的是,cmov指令并不是向后兼容的,所以虽然早在1995 Pentium Por时代,IA32处理器就已经支持条件传送指令了,但默认还是不用。
要用就显式说明,例如加上-march=i686编译选项,而对于i386则不会用cmov指令。
当然,现代的gcc有可能默认已经是i686。
假设有如下cMov.c文件
int absdiff(int x, int y) {
return x < y ? y-x : x-y;
}
如果用如下指令编译:
$ gcc -S -march=i386 -O1 -o cMov386.s
得到的cMov386.s文件将是:
.file "cMov.c"
.text
.globl _absdiff
.def _absdiff; .scl 2; .type 32; .endef
_absdiff:
LFB0:
.cfi_startproc
movl 4(%esp), %eax
movl 8(%esp), %edx
cmpl %edx, %eax
jge L2
subl %eax, %edx
movl %edx, %eax
ret
L2:
subl %edx, %eax
ret
.cfi_endproc
LFE0:
.ident "GCC: (GNU) 4.9.2"
如果用如下指令编译:
$ gcc -S -march=i686 -O1 -o cMov686.s
得到的cMov686.s文件将是:
.file "cMov.c"
.text
.globl _absdiff
.def _absdiff; .scl 2; .type 32; .endef
_absdiff:
LFB0:
.cfi_startproc
pushl %ebx
.cfi_def_cfa_offset 8
.cfi_offset 3, -8
movl 8(%esp), %ecx #get x
movl 12(%esp), %edx #get y
movl %edx, %ebx #Copy y to %ebx
subl %ecx, %ebx #%ebx = y - x
movl %ecx, %eax #Copy x
subl %edx, %eax #%eax = x - y
cmpl %edx, %ecx #Compare x:y
cmovl %ebx, %eax #if x < y, %eax = y-x
popl %ebx
.cfi_restore 3
.cfi_def_cfa_offset 4
ret
.cfi_endproc
LFE0:
.ident "GCC: (GNU) 4.9.2"
可以看出,条件指令代码反而更长,但由于其能带来性能优势。
条件传送指令的性能优势
条件传送指令或者更确切的说,分支预测的核心是CPU流水管线的并行优化。
比方说,今天想陪女友旅游,但是现在还不确定她喜欢去云南呢?还是青岛, 那么,通常的做法询问她并是等她回复。如果喜欢云南,打听云南的攻略,喜欢青岛就打听青岛的攻略
然而,你是一个缺乏耐心的人,总试图找更省时间的办法,而且你会影分身。于是,一个分身询问并等待回复,一个分身准备云南的行程,一个分身准备青岛的行程,反正这三件事情不冲突(指令级并行)。后来得到消息说想去云南,Ok,一心打听云南的攻略,订票订房。
这个例子可能不算很合适,毕竟现实中没有分身,且这样做比较费钱,但是CPU计算顶多费点电。 主要的核心是CPU可以同时做几件事情,只要不冲突。
从现代CPU更底层的角度还是,是处理器使用流水线(pipeline)来获得高性能。具体第4、5章详解。
无法用条件传送指令的情况
如下,如果用条件指令,不存在xp指针,却指向了0。只能用分支指令。而gcc足够智能来避免类似简单错误的。
int cread(int *xp) {
return (xp ? *xp : 0);
}
如下,如果用分支预测,则lcount++将被执行,而执行不应该执行。
int lcount = 0;
int fun(int x, int y) {
return x < y ? (lcount++, y-x) : x-y;
}
条件传送指令也有可能反而效率低下,例如当分支的任务量都很大时。
swich语句
switch语句根据一个整数索引值进行多重分支(multi-way branching)。 它不仅使代码可读性更好,而且switch通过使用跳转表(jump table)的数据结果同时也使得实现更高效。
跳转表是一个数组,表项i是一个代码段的地址。
跳转表的特点是,无论case有多少,时间上都是 O(1) 的。如果用if-else来写,则需要判断的次数很多,效率不高。
GCC也可以根据case的多少来判断是否用跳转表。如果case达到一定程度就用。
我们写一个简单的程序作为例子,假设有文件swich.c,其内容如下:
int switch_eg(int x, int n) {
int result = x;
switch (n) {
case 100:
result += 1;
break;
case 102:
result += 2;
case 103:
result += 3;
break;
case 104:
case 106:
result += 4;
break;
case 101:
result += 5;
break;
default:
result = 0;
}
return result;
}
编译为汇编后(gcc -O1 -S -o switch.s):
.file "switch.c"
.section .text.unlikely,"x"
LCOLDB0:
.text
LHOTB0:
.p2align 4,,15
.globl _switch_eg
.def _switch_eg; .scl 2; .type 32; .endef
_switch_eg:
LFB0:
.cfi_startproc
movl 8(%esp), %eax
subl $100, %eax #%eax = n - 100
cmpl $6, %eax
ja L9 #if %eax > 6 or < 0 jump to default
jmp *L4(,%eax,4) #jump to 4*%eax + L4
.section .rdata,"dr"
.align 4
L4:
.long L3 #4*0 + L4 ;case 100
.long L5 #4*1 + L4 ;case 101
.long L6 #4*2 + L4 ;case 102
.long L7 #4*3 + L4 ;case 103
.long L8 #4*4 + L4 ;case 104
.long L9 #4*5 + L4 ;default
.long L8 #4*6 + L4 ;case 106
.text
.p2align 4,,10
L6:
addl $2, 4(%esp) #case 102 result +=2
L7:
movl 4(%esp), %eax
addl $3, %eax #case 103 result +=3
ret
.p2align 4,,10
L8:
movl 4(%esp), %eax
addl $4, %eax #case 106 result +=4
ret
.p2align 4,,10
L3:
movl 4(%esp), %eax
addl $1, %eax #case 100 result +=1
ret
.p2align 4,,10
L5:
movl 4(%esp), %eax
addl $5, %eax #case 101 result +=5
ret
.p2align 4,,10
L9:
xorl %eax, %eax #default, will set %eax = 0
ret
.cfi_endproc
LFE0:
.section .text.unlikely,"x"
LCOLDE0:
.text
LHOTE0:
.ident "GCC: (GNU) 4.9.2"
通过上述的例子可以发现,实际上汇编将不同的case统统转化为数字, 这里数字的作用实际上是数组的标号,或者说偏移量
1) 首先将所有case数字[a, b]偏移到 [0, b-a]
2) 然后判断被测试的数n是否在[0, b-a]内,如果不在那么肯定是default了 注意如果n < 0 则最高位为1,那么对于unsigned是一个极大的数,所以判断条件
cmpl $6, %eax
ja L9
足够。
3) 对于顺序不是升序的情况,例如上述case 101放在后面,汇编将会将其按顺序排好
4) 对于case中没有的例子,填上,并指向default,例如没有case 105